Introduction
In February of this year, the Zhiyu GLM Coding Plan was launched and quickly sold out. Zhiyu subsequently upgraded the GLM Coding Plan, transitioning from Vibe Coding to Agentic Engineering. Interestingly, a recent influx of overseas developers is attempting to enter Chinese platforms to purchase the GLM Coding Plan.
As user and call volumes rapidly increase, the Coding Agent has become a true and rigorous stress test for large models. Issues that previously went unnoticed in ordinary chat scenarios have begun to surface in high concurrency, long context, and complex tool invocation. This marks a new set of challenges for inference optimization in the era of Coding Agents.
“This year is the decisive year for infrastructure.” If last year’s focus in large model competition was on “whose model is stronger,” this year the real game-changer is shifting to “whose infrastructure can withstand the pressure.”
On April 30, Zhiyu published a technical blog titled “Scaling Pain: Large-Scale Coding Agent Inference Practices,” which systematically disclosed breakthroughs in the underlying inference technology of the GLM-5 series models in large-scale Coding Agent invocation scenarios. This includes the identification and fixing of two critical bugs, a performance optimization innovation, and an unexpected breakthrough in monitoring mechanisms.
Additionally, the Zhiyu team contributed their accumulated inference engineering practices from the past six months back to the SGLang open-source community. This means that the relevant experiences may also assist in the inference optimization, throughput expansion, and stability of agent scenarios for more models in the future.
Scaling Pain: The Challenge of Large-Scale Inference
The belief in Scaling Law drives us to continuously break through model parameters and data scales, while also pushing the limits of infrastructure engineering, a process accompanied by inevitable growing pains, which we refer to as “Scaling Pain.”
As large model applications shift from simple dialogues to more complex and longer Coding Agent tasks, our inference infrastructure is experiencing unprecedented pressure, handling hundreds of millions of Coding Agent calls daily. In recent weeks, some users executing complex Coding Agent tasks with the GLM-5 series models have encountered various anomalies: garbled output, repetition, and occasional rare characters. These issues do not exist in standard inference environments but trigger only in high concurrency, long context Coding Agent scenarios, making them difficult to reproduce consistently.
After several weeks of deduction, investigation, and stress testing, we identified and fixed several independent underlying race condition bugs, and targeted optimizations were made to address the system bottlenecks, significantly improving the stability and efficiency of the inference system.
We will share the experiences and lessons learned from this exploration to collectively overcome the Scaling Pain of Coding Agent inference.
From Offline Reproduction to Anomaly Identification
Since March, we have observed three types of anomalies in online monitoring and user feedback for GLM-5: garbled output, repetition, and rare characters. These phenomena superficially resemble the common “dumbing down” seen in long context scenarios, but since we have not implemented any optimizations that reduce model accuracy, a more critical question arises: Do the anomalies stem from the model itself, or from the inference chain? If they originate from the model, anomalies would manifest as stable, repeatable behaviors for specific inputs; conversely, if anomalies are related to system pressure or runtime state, they are more likely to indicate issues in the inference infrastructure’s chain or state management.
During the initial investigation, we replayed user-reported bad cases locally and repeated the same batch of requests hundreds of times, but we could not reproduce the anomalies, indicating that it was likely not an issue with the model itself. To further simulate the pressure of the online environment, we desensitized the online logs while retaining the original concurrency distribution and request timing, conducting a full replay locally. Initially, we still could not reproduce the anomalies until we adjusted the PD separation ratio and continuously increased system load, simulating peak Prefill accumulation and Decode side KV Cache pressure. We then managed to reproduce anomalies stably 3-5 times in every ten thousand requests. This characteristic of being “unrelated to request content but related to system pressure” suggests that the problem may stem from inference state management under high load. Meanwhile, the frequency of anomalies reproduced offline remained lower than the frequency reported online, indicating that existing detection methods may have missed some cases or that some triggering scenarios were still uncovered.
Reliable identification of anomalous outputs became a new challenge. Among the three types of anomalies, repetition is relatively easy to detect, while garbled output and rare characters are more challenging. We attempted heuristic methods such as regular expressions and character set matching, as well as model-based discrimination approaches, but the former suffered from significant false negatives and false positives, while the latter struggled to meet the efficiency requirements of large-scale ablation experiments. These limitations turned anomaly detection itself into a bottleneck in the localization process.
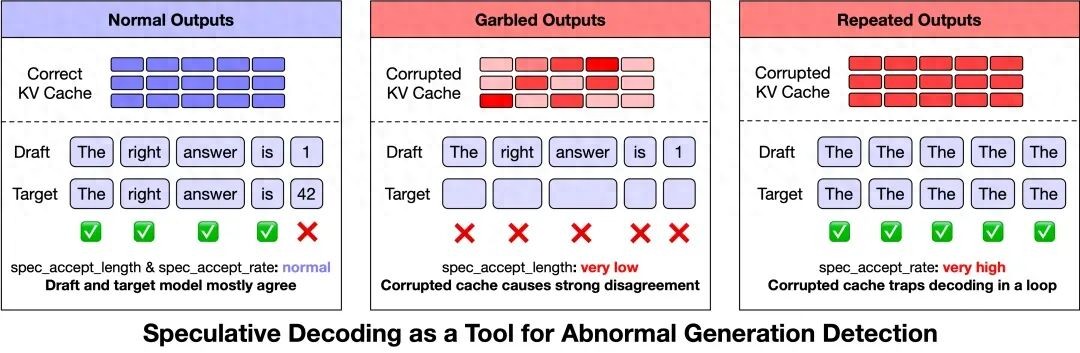 Figure 1: Speculative sampling metrics can serve as important references for anomaly detection.
Figure 1: Speculative sampling metrics can serve as important references for anomaly detection.
After repeatedly analyzing inference logs, we discovered an unexpected entry point: speculative decoding (Speculative Decoding) metrics can serve as important references for anomaly detection. Originally a performance optimization technique, speculative decoding generates candidate tokens from a draft model, which are then verified and accepted by the target model, thereby improving decode efficiency without altering the final output distribution. As shown in Figure 1, we observed that two metrics (spec_accept_length: the length of the draft token prefix accepted by the target model; spec_accept_rate: the proportion of draft tokens accepted) exhibited stable patterns during anomalies:
- Garbled output and rare characters: Typically accompanied by a very low spec_accept_length, indicating that almost all candidate tokens generated by the draft model were rejected by the target model, suggesting a significant deviation between the KV Cache state seen by the target model and the expectations of the draft model.
- Repetition: Typically accompanied by a high spec_accept_rate, indicating that a damaged KV Cache may degrade the attention pattern and push the generation process into a high-confidence repetitive loop.
Based on these observations, we further implemented an online anomaly monitoring strategy: when spec_accept_length remains below 1.4 and the generated length exceeds 128 tokens, or when spec_accept_rate exceeds 0.96, the system actively aborts the current generation and hands the request over to the load balancer for a retry. This strategy expands speculative sampling from a pure performance optimization technique to a real-time monitoring signal for output quality, becoming a key tool in subsequent ablation experiments.
BugFix: KV Cache Race Conditions under PD Separation Architecture
After observing a clear correlation between anomalous outputs and concurrent pressure, we further analyzed the causes. By examining the request lifecycle and the execution timing of PD separation in the inference engine, we identified that the issue stemmed from inconsistencies between the request lifecycle and the timing of KV Cache recycling and reuse, leading to KV Cache reuse conflicts.
1. Cause Analysis: KV Cache Reuse Race Condition Triggered by Asynchronous Abort
To limit tail latency, we introduced a timeout-based request termination mechanism in the inference engine: when the Prefill stage does not complete within the specified time, the Decode side aborts the request and recycles its occupied KV Cache resources. However, this abort signal was not correctly propagated to the Prefill side, and the Decode side also lacked sufficient information to determine whether the KV Cache could be safely recycled and reused. Therefore, after the Decode aborts and reallocates the corresponding KV Cache space to a new request, any previously initiated RDMA writes and ongoing Prefill computations continue to execute without being synchronized for cancellation.
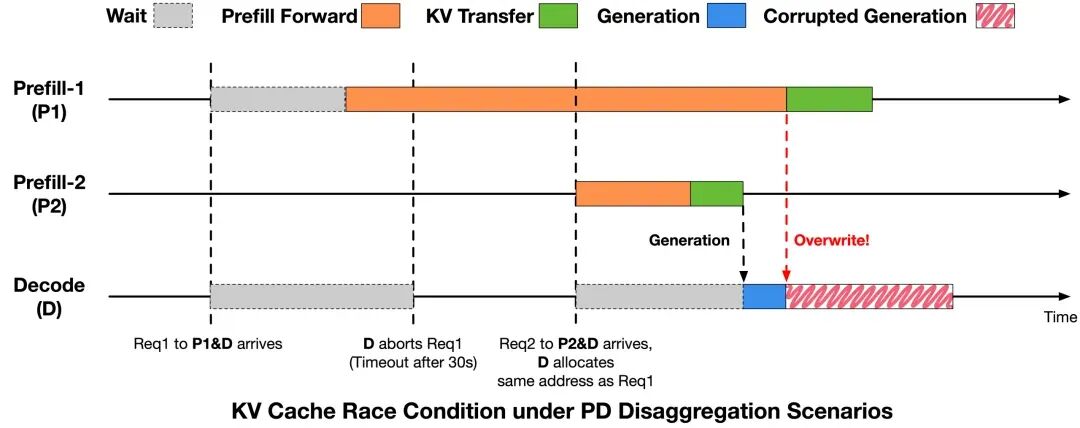 Figure 2: KV Cache race condition in the PD separation scenario.
Figure 2: KV Cache race condition in the PD separation scenario.
Figure 2 illustrates the timing relationship between two requests interacting between Prefill and Decode, and the resulting KV Cache race condition.
In the initial stage, Req1 is sent to Prefill-1 (P1) and Decode (D). Due to scheduling or queuing reasons, Req1 experiences a delay before starting Prefill Forward at P1. Meanwhile, the Decode side does not receive the corresponding KV Cache data for a period, triggering the timeout mechanism and aborting Req1.
Subsequently, the Decode side recycles the KV Cache slots occupied by Req1 but does not correctly notify P1. Shortly after, a new request, Req2, arrives and is assigned to Prefill-2 (P2) and Decode. Due to memory reuse strategies, Req2 is allocated to the same KV Cache address as Req1. P2 begins executing Prefill Forward and completes KV Transfer in a short time, allowing the Decode side to enter the generation phase.
Meanwhile, the KV Cache write initiated by P1 for Req1 continues, writing data into the memory area that has been reused by Req2, thus overwriting part of Req2’s KV Cache. Ultimately, Req2 reads the overwritten data during the Decode phase, leading to anomalous generation results.
2. Fix Proposal: Ensuring Temporal Consistency in KV Cache Release
To eliminate the above race condition, we introduced stricter temporal constraints in the inference engine, establishing explicit synchronization between request termination and KV Cache write completion.
Specifically, after triggering an abort, the Decode side sends a notification to the Prefill side. Prefill only returns a “releasable” signal when the following conditions are met: the relevant RDMA writes have not yet started, or all submitted writes have been completed. The Decode side is only allowed to recycle and reuse the corresponding KV Cache slots after receiving this confirmation. This mechanism ensures that KV writes do not cross the memory reuse boundary, thus avoiding KV Cache overwrites across requests.
Fix Effect: After this fix was implemented, the occurrence rate of anomalous outputs dropped from about 0.0013% to below 0.0003%. The results indicate that in a PD separation architecture, explicit consistency constraints need to be established for cross-node data transmission and memory reuse to avoid similar issues.
BugFix: Missing Loading Timing for HiCache
The Coding Agent scenario significantly increases input lengths (averaging over 70K tokens) while also having a high prefix reuse rate. Such loads make HiCache (multi-level KV Cache) a key optimization tool in online services. However, in cases where KV Cache swapping and computation overlap, the current implementation fails to ensure that data is fully loaded before use, leading to the possibility of accessing unready KV Cache.
1. Cause Analysis: Read-Before-Ready Due to Missing Pipeline Synchronization
By analyzing the execution timing of HiCache, we pinpointed the problem in the DSA HiCache’s cache reading path. The system asynchronously swaps in historical prefix caches from CPU memory and overlaps the execution of Load Stream and Forward Stream to improve throughput.
As shown in Figure 3(a), Load Stream is responsible for loading KV Cache and Indexer Cache, while Forward Stream sequentially executes Index calculations and subsequent Sparse Attention. Theoretically, the Indexer computation in the Forward Stream should start only after the corresponding Indexer Cache has been fully loaded. However, in the original implementation, this dependency was not explicitly expressed.
Specifically, the Indexer operator did not establish synchronization constraints for the completion of Load Indexer Cache when it started (the red dashed area in Figure 3). Therefore, the Forward Stream could begin execution before the Load Stream completed data loading, resulting in a Read-Before-Ready access pattern, where data is read before it is fully loaded.
This issue can cause the Index computation to execute based on incomplete or uninitialized data, subsequently affecting the results of the following Sparse Attention calculations and ultimately reflecting as output anomalies.
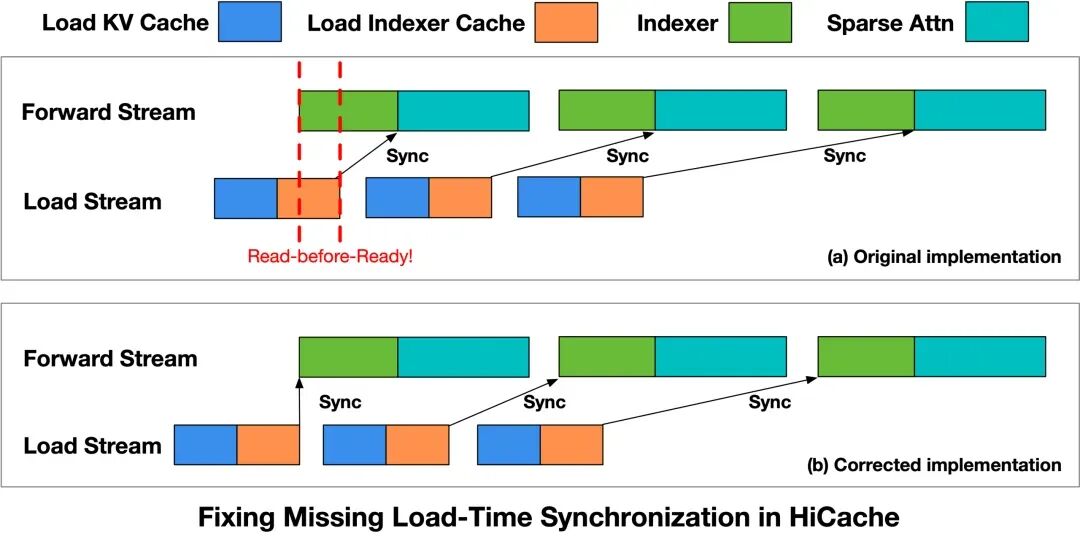 Figure 3: HiCache reading pipeline timing anomalies and fix illustration.
Figure 3: HiCache reading pipeline timing anomalies and fix illustration.
2. Fix Proposal: Restructuring Operator Pipeline Atomicity
To address this issue, we modified the reading pipeline of HiCache (as shown in Figure 3(b)), introducing explicit synchronization constraints between data loading and computation:
- Explicit Synchronization Constraints: Introduce a synchronization point with Load Stream before starting the Indexer operator to ensure that the corresponding layer’s Indexer Cache is fully loaded. The Forward Stream only starts computation after the data is ready, thus avoiding Read-Before-Ready access.
After this fix was implemented, anomalies caused by inconsistent execution timing completely disappeared under the same load conditions, and system behavior stabilized. This fix has been submitted via Pull Request to the SGLang community.
Optimization: LayerSplit for KV Cache Hierarchical Storage
The two race conditions mentioned above reveal a common system bottleneck: in long context Coding Agent Serving scenarios, the Prefill stage dominates system performance.
To control the TTFT caused by Prefill queuing, we introduced timeout aborts; to alleviate the capacity pressure on Prefill-side KV Cache, we introduced HiCache. After fixing these state consistency issues, we returned to the bottleneck itself: how to enhance Prefill throughput and reduce Prefill-side KV Cache memory pressure. To this end, we designed and implemented a KV Cache hierarchical storage scheme called LayerSplit.
Coding Agent loads typically exhibit characteristics of long context lengths and high Prefix Cache hit rates. In this scenario, the Prefill stage often becomes the main performance bottleneck, making Context Parallel (CP) the primary parallel strategy for online Prefill nodes. However, the existing SGLang open-source implementation suffers from redundant KV Cache storage issues, causing limited KV Cache capacity to restrict GPU computation resource utilization.
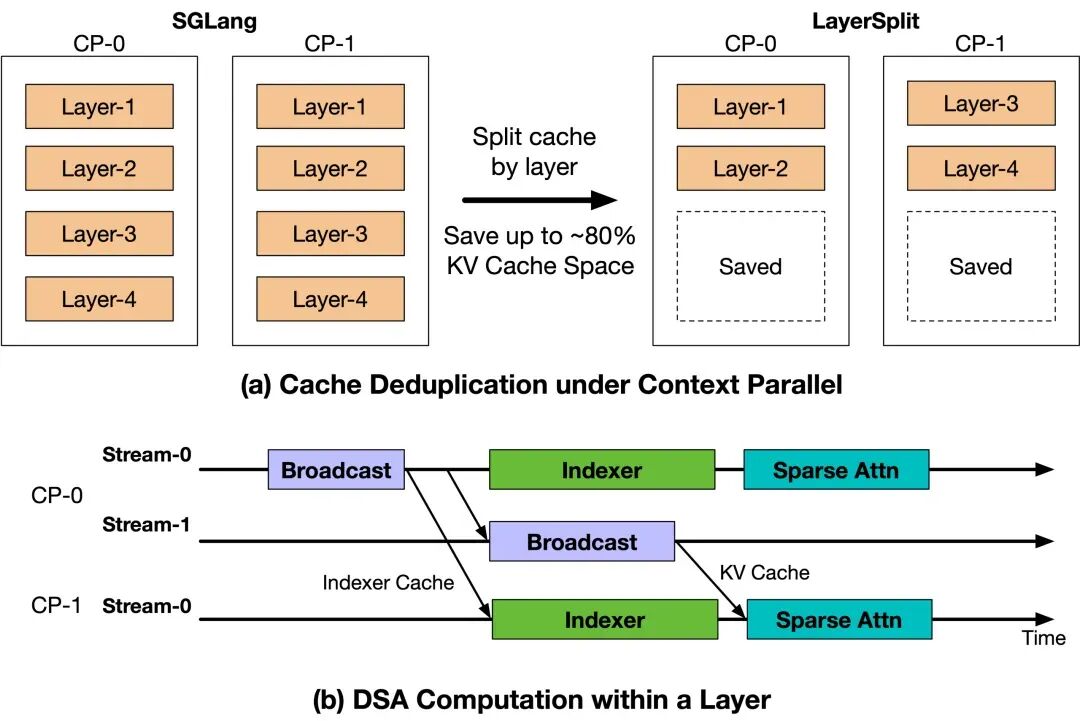 Figure 4: LayerSplit, KV Cache hierarchical storage scheme.
Figure 4: LayerSplit, KV Cache hierarchical storage scheme.
To address this issue, we designed and implemented a KV Cache hierarchical storage scheme (LayerSplit). In this scheme, each GPU no longer retains the KV Cache for all layers but only holds the KV Cache for certain layers (as shown in Figure 4(a)), significantly reducing the memory occupation of a single card.
During computation, different CP ranks collaboratively complete Prefill as illustrated in Figure 4(b). Specifically, the rank holding a particular layer’s KV Cache broadcasts that layer’s Cache to other relevant ranks before executing Attention calculations. To reduce communication overhead, we further designed an overlapping mechanism for KV Cache broadcasting and indexer computation, allowing both to mask each other in time. Ultimately, the entire process introduced only the additional overhead of Indexer Cache broadcasting, which is about 1/8 the scale of KV Cache, thus keeping overall communication costs low and having a negligible impact on performance.
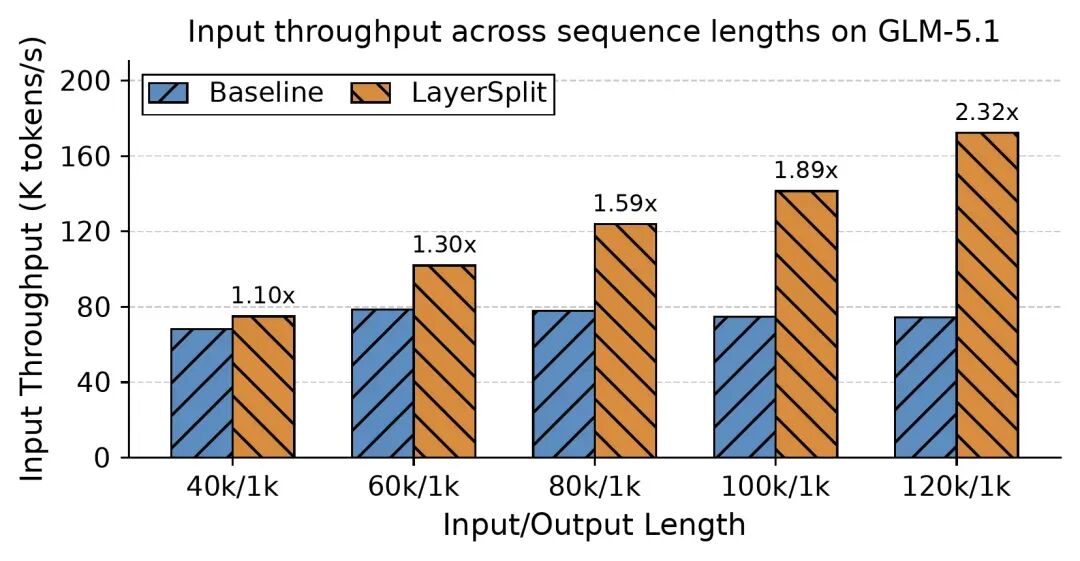 Figure 5: Performance improvements of GLM-5.1 + LayerSplit across different lengths.
Figure 5: Performance improvements of GLM-5.1 + LayerSplit across different lengths.
Figure 5 shows the performance improvements brought by this optimization under conditions of a 90% cache hit rate, with request lengths ranging from 40k to 120k. Experimental results indicate that the system throughput increased between 10% and 132%, with more significant gains observed as context length increased. Overall, this optimization significantly enhanced the system’s processing capability in Coding Agent scenarios.
Conclusion
As intelligence truly enters high concurrency and long context Coding Agent scenarios, the challenges of inference infrastructure extend beyond throughput, latency, and availability; maintaining output quality becomes crucial. Every pursuit of Scaling Law must be supported by equally strong systems engineering. We share these experiences in hopes of helping the community avoid some detours and collaboratively refine the inference infrastructure capable of supporting the future of AGI.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.