Introduction
Recently, Anthropic updated its consumer terms, inciting anger among users who recalled the company’s previous promises. Initially, Anthropic firmly stated that it would not use user data to train its models. This change not only contradicts that stance but also brings past grievances to light.
Policy Update Details
The recent update to Anthropic’s terms has stirred significant backlash. In this update, Anthropic has changed its previous commitment not to use user data for model training, now giving existing users a choice: whether to allow their data to be used for model training.
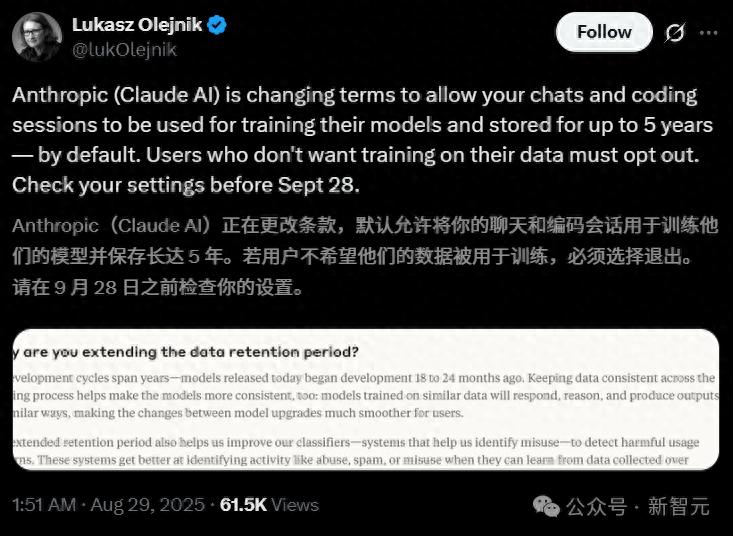
On the surface, Anthropic claims to give users a “choice,” but the decision must be made within a month. New users will have to make their choice upon registration, while existing users must decide by September 28:
- If users choose to accept, the change takes effect immediately, but only for new or restarted chat and programming sessions.
- After September 28, users must make a choice in the model training settings to continue using Claude.
Additionally, another change in the terms states:
- If users opt to allow their data to be used for model training, the data retention period will be extended to five years. Deleted conversations with Claude will not be used for future model training.
- If users do not opt-in, the existing 30-day data retention policy remains in effect.
The consumer users referred to here include all users of Claude’s free, professional, and Max versions, including Claude Code. However, users of Claude Gov, Claude for Work, Claude for Education, or those accessing via API are not affected.
User Reactions
Users have expressed outrage over Anthropic’s actions!

Not only the policy but also the UI design has been criticized for being misleading and easy to fall into traps.

This so-called “wordplay” is familiar to anyone who has installed software on a computer in the past.
Moreover, Anthropic’s questionable practices do not stop there. User “Ahmad” highlighted a series of Anthropic’s past betrayals in a tweet:
- All conversations and code are retained for five years and used for model training.
- Users are secretly switched to a 1.58 bit “reduced” quantization model during the day.
- Plus members cannot use the strongest Opus 4 model in Claude Code.
- Six weeks ago, the usage limit for the Max plan was halved without any notification.
- The specific weekly usage limits are never disclosed.
- The advertised 5x/20x usage plans only provide 3x/8x of the Plus plan’s limits.
- DMCA notices are randomly issued, leading to the removal of many code repositories related to Claude Code, affecting personal projects.
- Windsurf users cannot access Claude 4.
- Access to the OpenAI API has been cut off.

The Value of User Data
In a blog post about this policy update, Anthropic framed the changes as giving users a choice, claiming:
If users do not opt-out, it will help improve model safety, enhance the accuracy of harmful content detection systems, and reduce the chances of marking benign conversations.
Furthermore, users who accept the new policy are told it will help enhance future Claude models’ coding, analytical, and reasoning skills, ultimately benefiting all users.
However, the truth behind this grandiose rhetoric is far more complex.

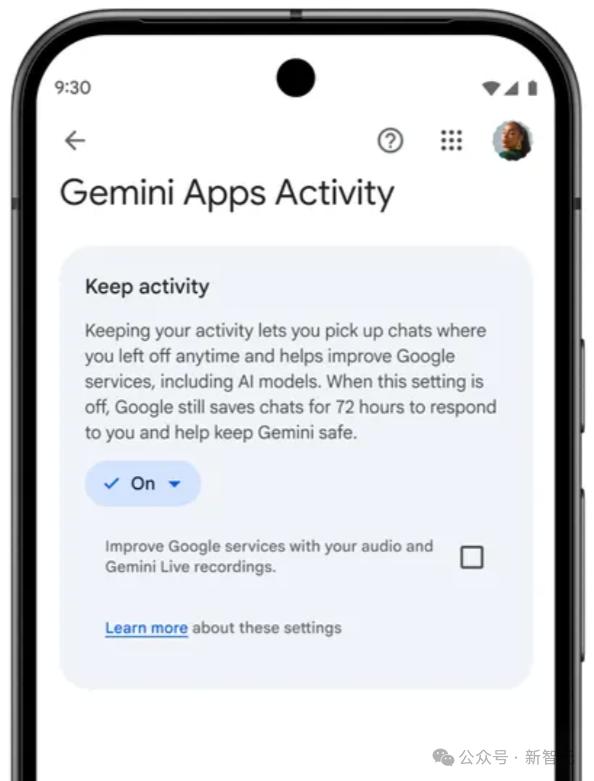
From an industry perspective, Anthropic’s update is not an isolated incident. Large models become smarter only when trained on more real user data. Consequently, companies are constantly grappling with how to secure user data to improve their models. For instance, Google recently made a similar adjustment, renaming “Gemini Apps Activity” to “Keep Activity.” Google stated that when this setting is enabled, some uploaded samples will be used to “help improve Google services for everyone” starting September 2.
Like Google, OpenAI, and other major model companies, Anthropic’s thirst for data far outweighs its concern for maintaining user brand loyalty. Access to millions of Claude user interactions provides Anthropic with more real-world programming context, enhancing its models’ competitive edge against OpenAI and Google.
Thus, it is not hard to imagine that the true intent behind Anthropic’s policy update is to tap into the “gold mine” of user data.

User Privacy Concerns
Historically, Anthropic’s biggest draw for users was its commitment to strict consumer data privacy. From the launch of Claude, the company firmly stated it would not use user data for model training. Previously, users of Anthropic’s consumer products were informed that their prompts and conversations would be automatically deleted from the company’s backend within 30 days—unless legally required to retain them longer or if marked as violations (in which case, inputs and outputs could be retained for up to two years).
Now, Anthropic requires new and existing users to choose whether to allow their data to be used for model training, with existing users having only a month to decide. Furthermore, the data retention period has been extended to five years.

The types of user data that may be used for model training include:
All relevant conversations, any content, custom styles, or session preferences, as well as data collected while using Claude for Chrome. This data does not include original content from connectors (e.g., Google Drive) or remote and local MCP servers, but if they are directly copied into conversations with Claude, they may be included.

Who Protects User Privacy?
As these large companies “quietly” change policies, who protects user privacy? Their constantly changing policies create significant confusion for users. Moreover, it seems these companies deliberately downplay this aspect during policy updates.
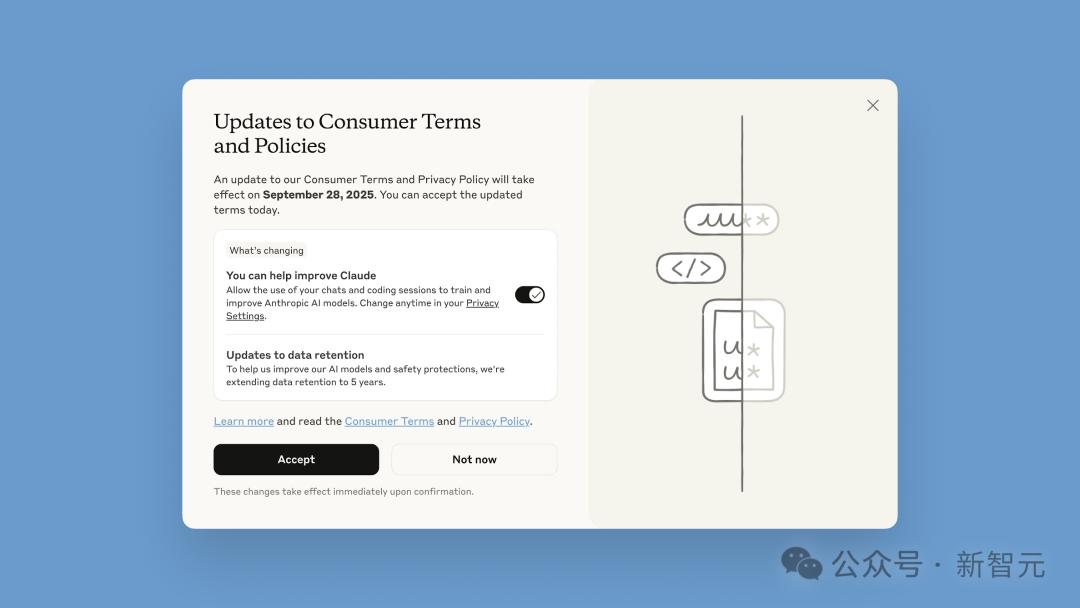
For instance, in Anthropic’s recent update interface, existing users are greeted with a large-font title—“Consumer Terms and Policy Update”—with a prominent black “Accept” button on the left. Below the button is a small line of text and a smaller toggle switch for granting training permission—set to “on” by default.
This design raises widespread concerns: many users may inadvertently agree to data sharing by quickly clicking “Accept” without noticing.
Anthropic’s policy adjustment seems to reflect a broader industry trend in data policies. Observing the AI industry abroad, major players like Anthropic, OpenAI, and Google are facing increasing scrutiny due to their data retention practices.
For example, recently, to address a copyright lawsuit from The New York Times, OpenAI publicly acknowledged for the first time that it had been quietly retaining deleted and temporary chat records since mid-May. After this revelation, users were shocked to learn that their deleted ChatGPT chat records had been archived for legal scrutiny.
Returning to Anthropic’s change in consumer terms, it reflects the growing public concern and anxiety regarding AI privacy. As “user data” becomes a key factor in the competition among large models, how to maintain competitive advantages while protecting user data privacy has become a crucial challenge for all major model manufacturers.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.